SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
文章目的是减少网络的计算量。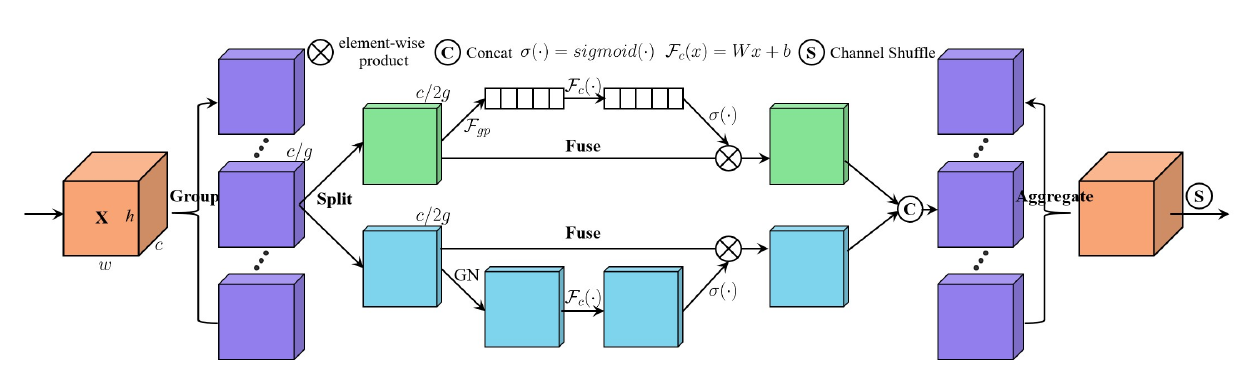
1 | class sa_layer(nn.Module): |
与之前不同的是:
- 在SA使用了Group Norm在代码中看来和INSNorm是一样的效果。
- 首先对feature map进行group,将其分为G个group然后在每个group中进行计算。
- CA、SA得到mask后,使用了 $W_i \in \mathbb{R}^{C/2G\times 1 \times 1}; R_i \in \mathbb{R}^{C/2G\times 1 \times 1}$ 作为weight 和bias。这两个是可训练的参数。初始化为0,1.
感觉文章没什么创新点。